Problem
How teachers facilitate classroom discussions profoundly shapes learning, but manual talk move coding cannot scale to support teacher development. While LLMs offer automation potential, existing work focuses on Western English contexts and treats classification as the end goal—missing how teacher expertise shapes how moves are executed.
Solution
We fine-tune LLMs on Hong Kong Cantonese math classrooms (7,518 utterances, 32 teachers), then probe embeddings to surface expertise patterns:
Key Results:
- Qwen3-8B: 81.4% micro-F1, 76.9% macro-F1 on 10-category talk move classification
- Teacher expertise linearly recoverable from embeddings (79% balanced accuracy)
- K-means clustering reveals three discourse styles distinguished by execution quality, not just move frequency
Key Insight: Experts and novices use similar talk move structures, but experts integrate conceptual connections within utterances while novices sequentialize them—a latent pattern that traditional linguistic analyses miss.
Methods
Dataset: 7,518 utterances from 32 Hong Kong upper-primary math teachers (16 schools, 64 lessons), annotated with 10 talk move categories. Stratified by experience: Novice (≤5 yrs, n=8), Experienced (≥10 yrs, n=17).
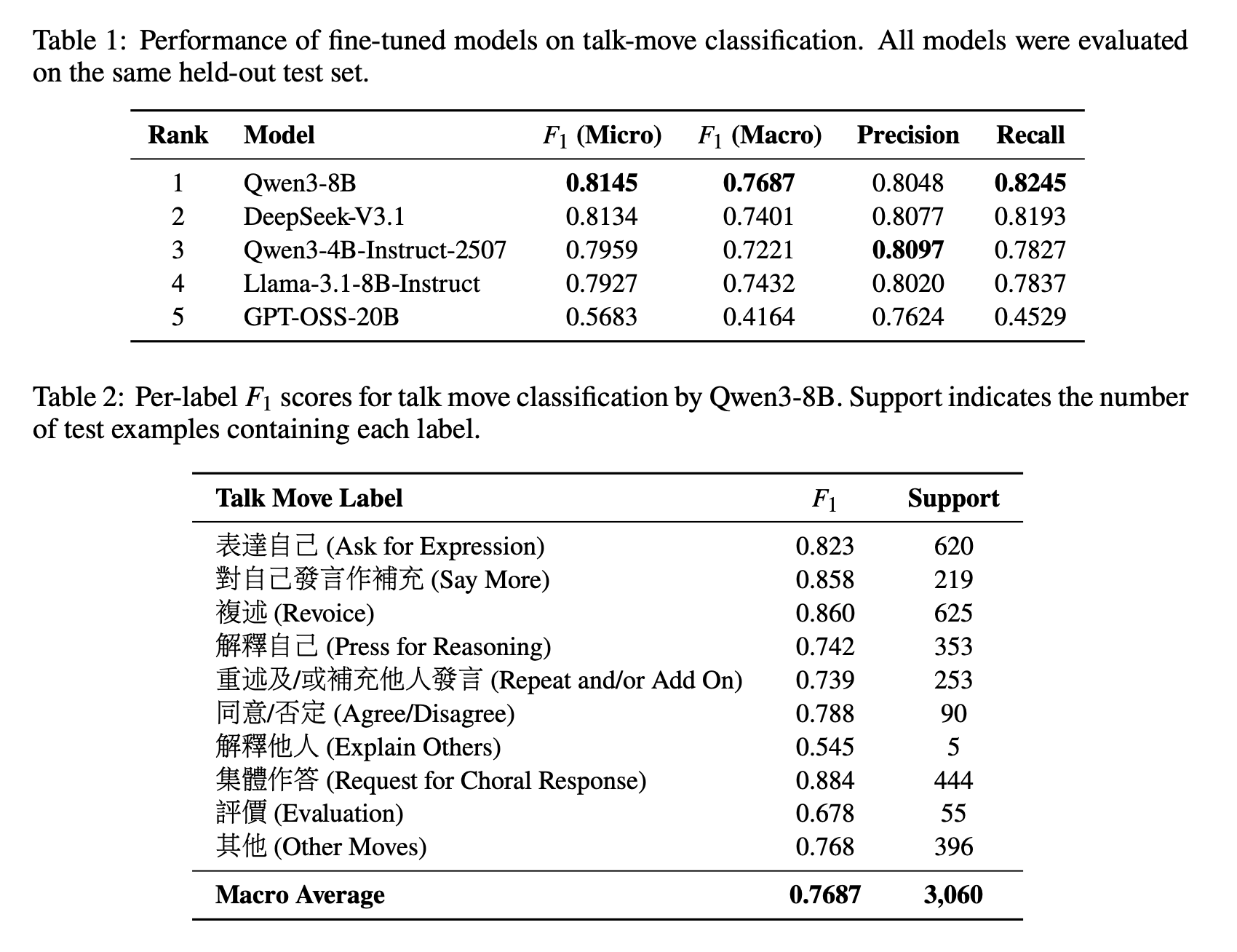
Stage 1: Fine-Tuning with LoRA-adapted Qwen3-8B with ±6-utterance context windows, inverse-frequency loss weighting. Trained with Tinker from Thinking Machines Lab. Best result: micro-F1 0.814, macro-F1 0.769.
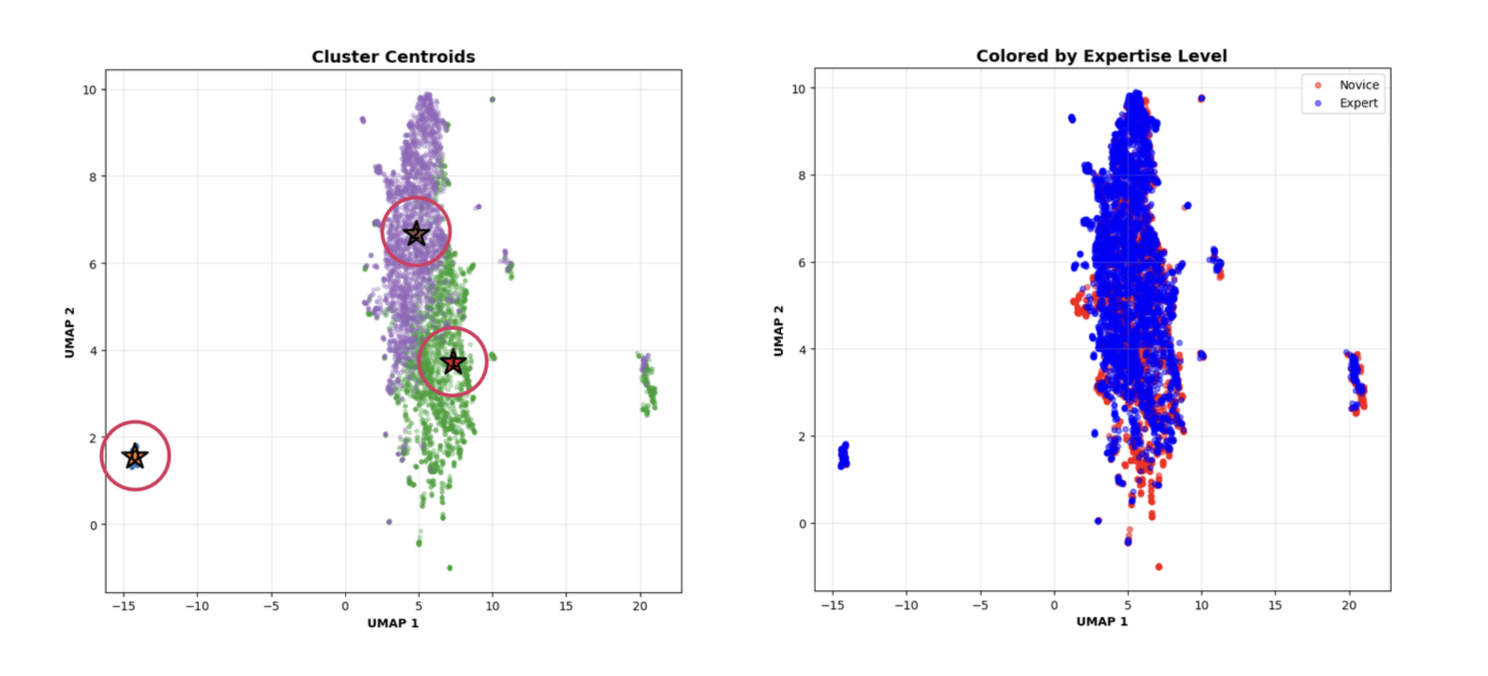
Stage 2: Embedding analysis extracting 4,096-dim final-layer embeddings with character-level offset mapping. Statistical testing (Bonferroni-corrected t-tests) identifies 348 dimensions that reliably distinguish expertise. ℓ2-regularized logistic regression achieves 79% balanced accuracy; K-means (k=3) reveals three discourse clusters (χ²=256.7, p<10⁻⁵⁶).
Three Discovered Discourse Clusters
Implications
Embedding analysis surfaces execution quality, not just move frequency. Experts and novices use similar talk move structures, but experts integrate conceptual connections while novices sequentialize them. This is a latent pattern that traditional feature engineering misses.
Domain-specific fine-tuning enables cross-cultural discourse analysis. Qwen3-8B’s strong performance on culturally characteristic moves (Choral Response, Revoice) shows open-weight models can learn context-specific pedagogical practices beyond Western norms.
Design implication: Linear separability of expertise enables formative tools that identify low-quality move realizations or suggest experienced-cluster examples. However, these signals reflect Hong Kong math norms and should not be treated as universal “good teaching” markers.